Kickstart your GraphQL API with Hasura.
Hasura can accelerate backend development by automating the implementation of simple CRUD endpoints. Business logic can still be implemented using remote schemas, webhooks, and database triggers/functions.
Introduction
Software projects are all about using your available development time most efficiently. In this post, we are going to explore how we can save time on our backend endpoints by using Hasura GraphQL engine. We will do this by implementing a backend system for our fictional pizzeria. Finally, we will discuss the implementation.
The code found in this post can be also found from here. I will refer to files found in the repository later. If you want to run the code examples you will need hasura cli, docker and docker-compose installed.
Requirements
Our requirements for the pizzeria-api are as follows:
-
Allow customers place orders.
-
Allow customers to receive updates to their order.
-
Employees must have a dashboard where they can see a list of all active orders. The dashboard must be real time.
Implementation
We will use Hasura GraphQL engine for the API implementation. To do this we will do the following:
-
Create a PostgreSQL database
-
Define some Hasura metadata
-
Implement a microservice using NodeJS and use Hasura's remote schema feature
Database
The database will be used to save all of our data. We will define the database with the following script:
CREATE TABLE topping (
id BIGSERIAL PRIMARY KEY,
name TEXT NOT NULL
);
CREATE TABLE pizza (
id BIGSERIAL PRIMARY KEY,
name TEXT NOT NULL,
price MONEY NOT NULL
);
CREATE TABLE pizza_topping (
id BIGSERIAL PRIMARY KEY,
pizza_id BIGINT REFERENCES pizza(id),
topping_id BIGINT REFERENCES topping(id)
);
CREATE INDEX ON pizza_topping(pizza_id);
CREATE INDEX ON pizza_topping(topping_id);
CREATE TABLE order_status (
status TEXT PRIMARY KEY
);
INSERT INTO order_status (status) VALUES ('NEW');
INSERT INTO order_status (status) VALUES ('RECEIVED');
INSERT INTO order_status (status) VALUES ('IN_PROGRESS');
INSERT INTO order_status (status) VALUES ('READY');
CREATE TABLE "order" (
id BIGSERIAL PRIMARY KEY,
created_at TIMESTAMP NOT NULL DEFAULT NOW (),
user_id TEXT NOT NULL,
pizza JSONB NOT NULL,
status TEXT NOT NULL REFERENCES order_status(status)
);
CREATE INDEX ON "order"(status);
SQL
The migration file is located in the migrations directory of the example code. You can apply the migration by using the following command:
hasura migrate apply
Hasura metadata
Hasura metadata contains the following information:
-
Tracked tables
-
Tracked relations
-
Authorization rules
-
Remote schemas
-
Webhook event handlers
Table tracking means that Hasura will add the table to the GraphQL schema and implement CRUD operations for it.
Relationship tracking means that you can navigate the relations using the GraphQL schema. For example, you might have a field called "toppings" in the pizza-type that when queried returns all the toppings related to the pizza.
With authorization rules you can define role-based access control for individual columns. Rules can be either static or dynamic. Static rules just allow/deny access to specific columns. Dynamic rules allow/deny access based on an expression, for example, if user_id column matches the value of x-hasura-user-id header the access is granted.
Remote schemas are GraphQL schemas that can be stitched to the main schema. This will allow you to implement custom GraphQL types and resolvers for your specific needs.
Webhook event handlers allow you to add an endpoint that Hasura will call when something happens in the database.
Table tracking
Let's instruct Hasura to track all tables by clicking "add all".
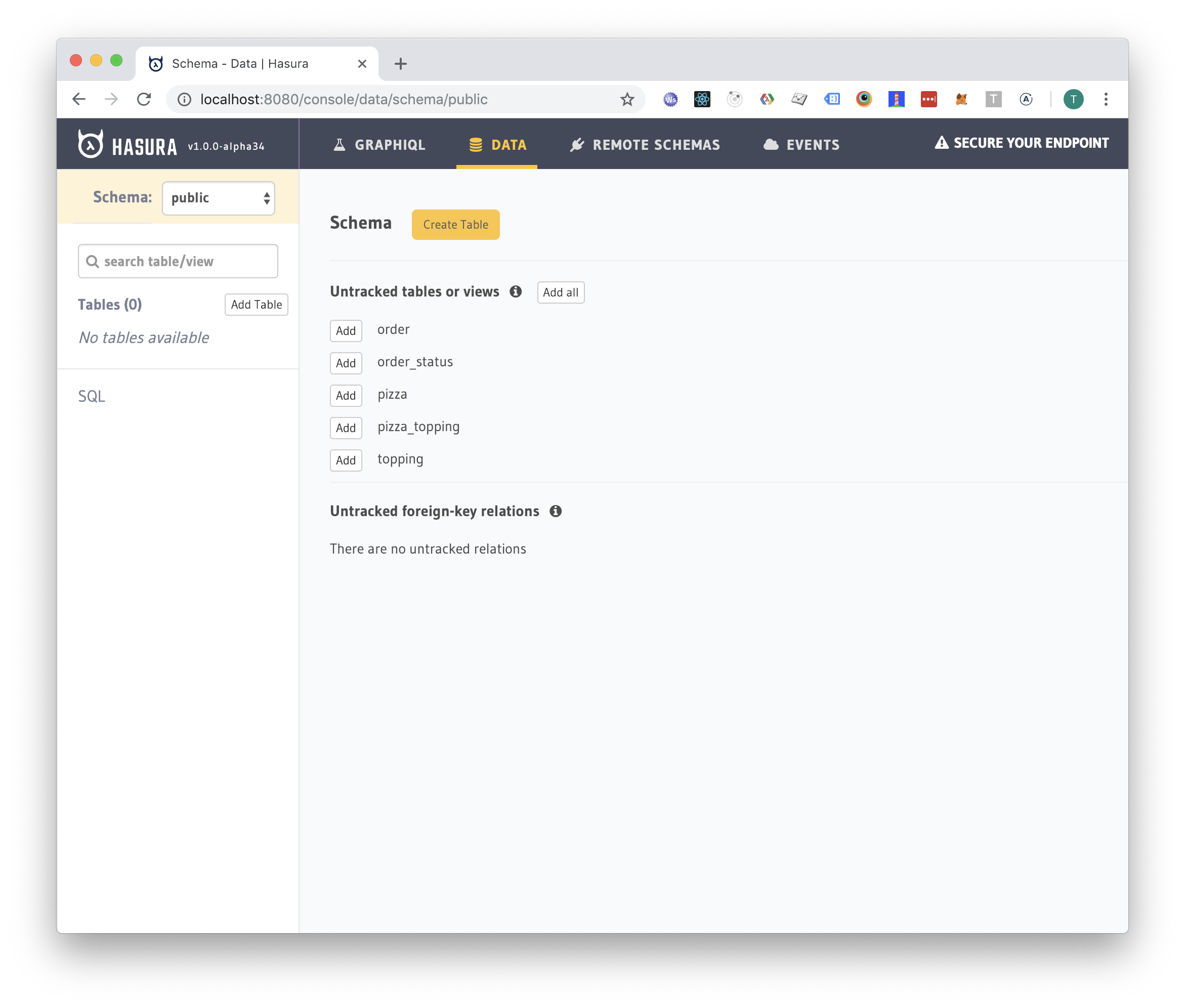
Next thing to do is to add relationship tracking information for each table:
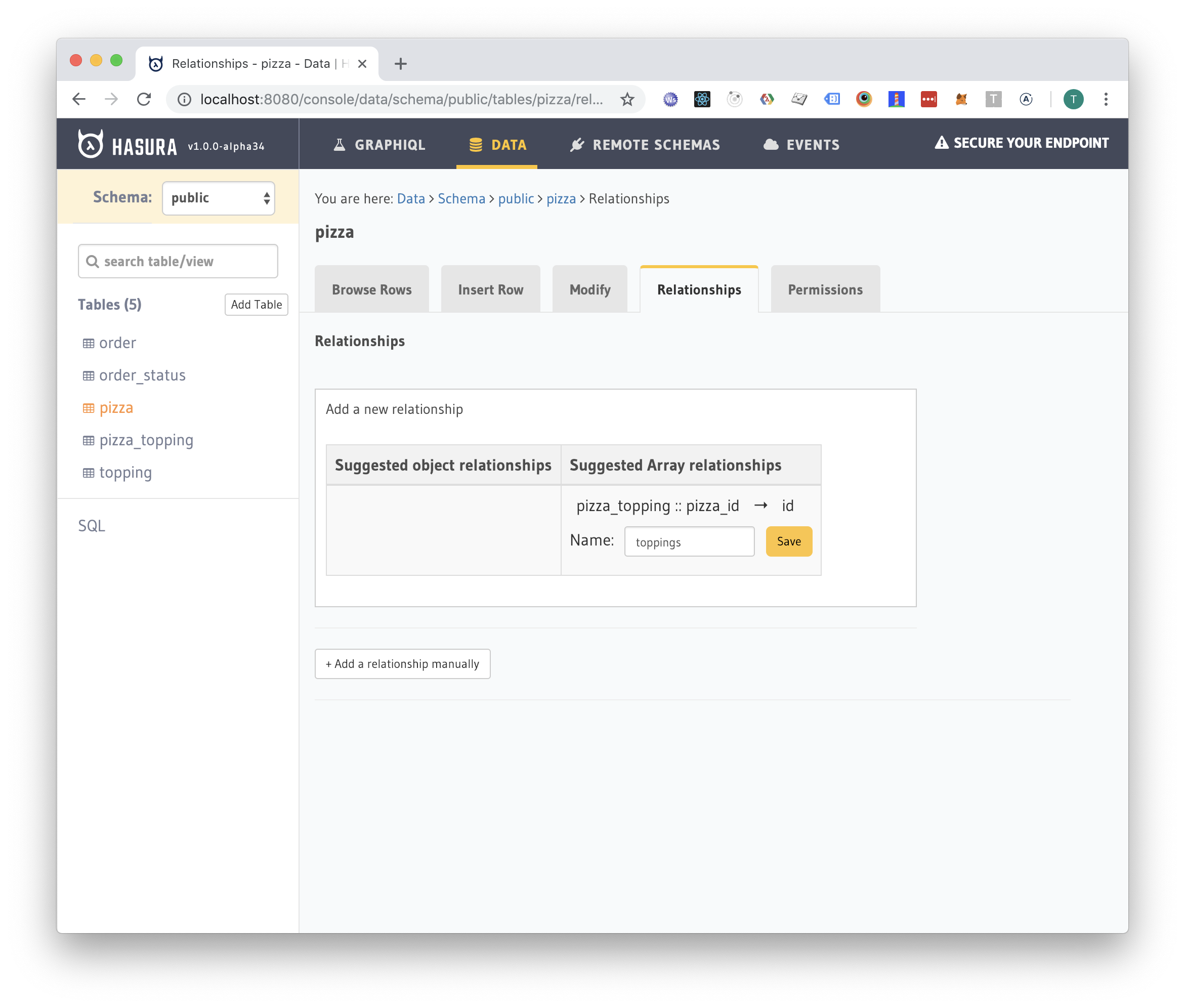
Track relationships example
Authentication
Before we move to authorization, let's set up a quick authentication mechanism by using Auth0.
Hasura has an excellent tutorial for setting up Auth0. But for the impatient below is the TL;DR; version of the tutorial:
-
Create auth0 account, tenant and application.
-
Use this tool to create a JWT config.
-
Pass the JWT config as environment variable
HASURA_GRAPHQL_JWT_SECRETas seen in the docker-compose.yml.
Authorization rules
After setting up authentication we are going to implement some access control. We will do this by adding the authorization metadata using Hasura console.
Our goal is to implement the following access control for the user role:
-
The user can see all the pizzas and toppings
-
The user can see his own orders
First, let's give the user permission to select his own orders. We will add a custom check that will validate that the user_id in the database row will match the x-hasura-user-id header.
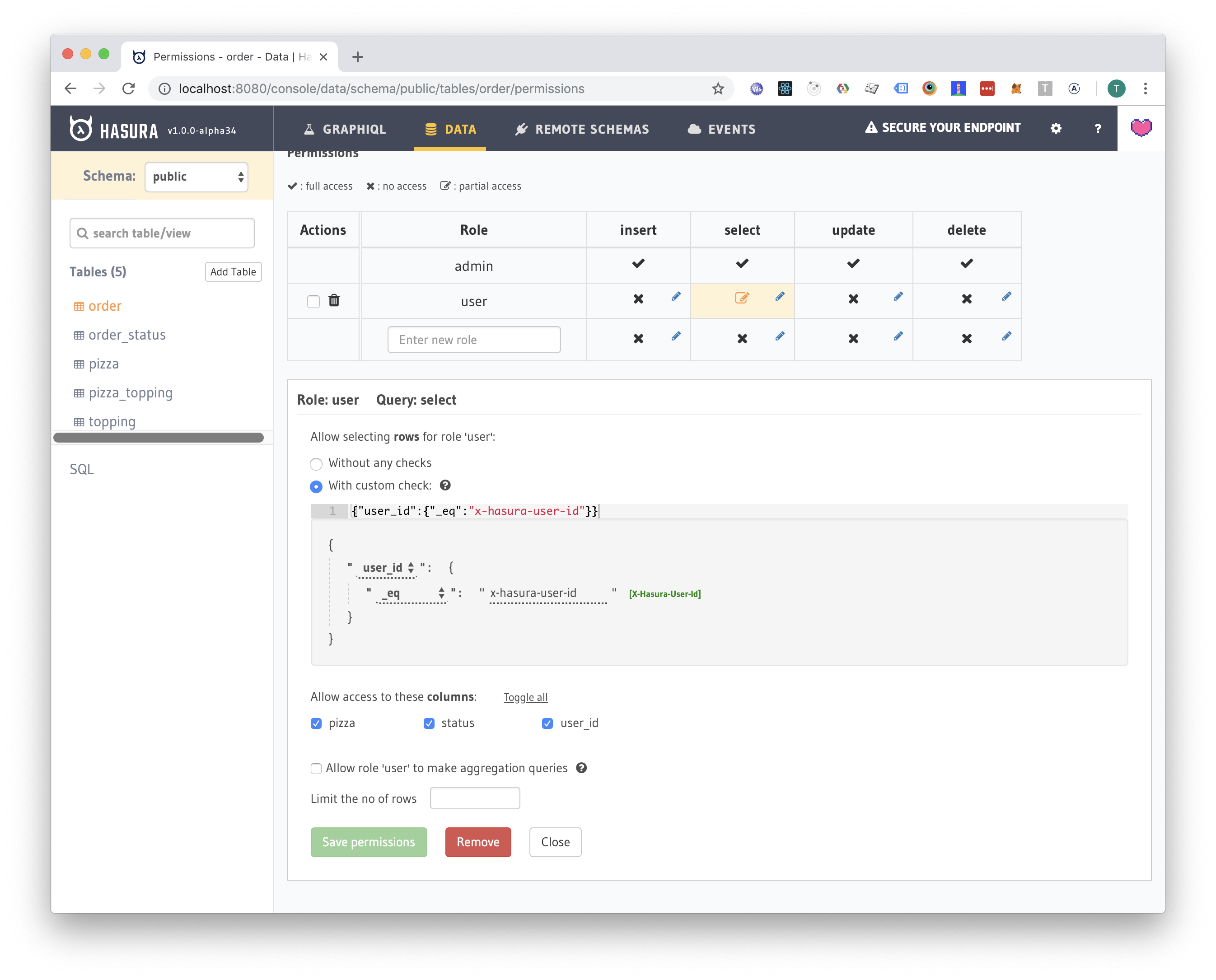
Order permissions
Next, let's allow the user to select all pizzas and toppings (he probably wants to see a menu):
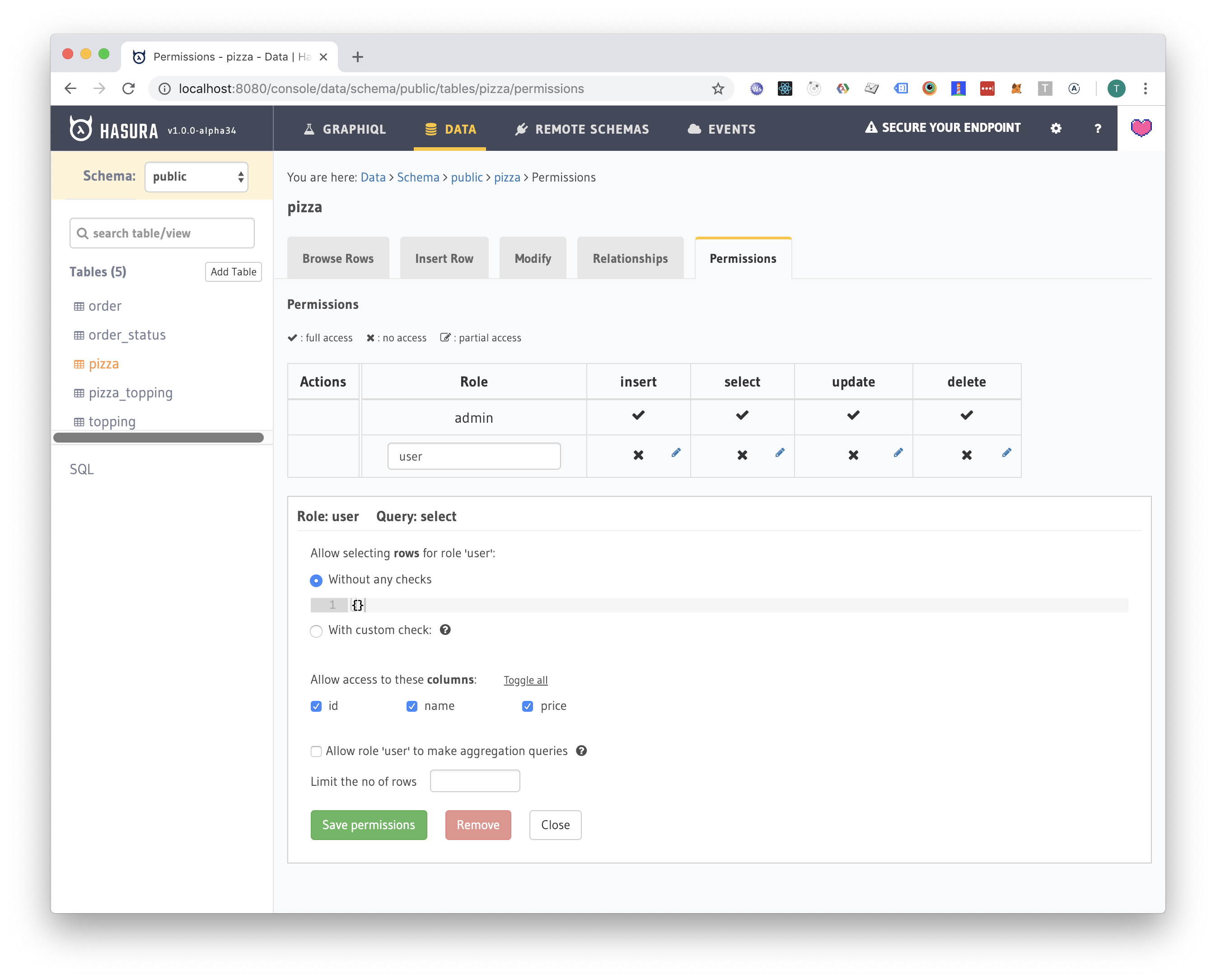
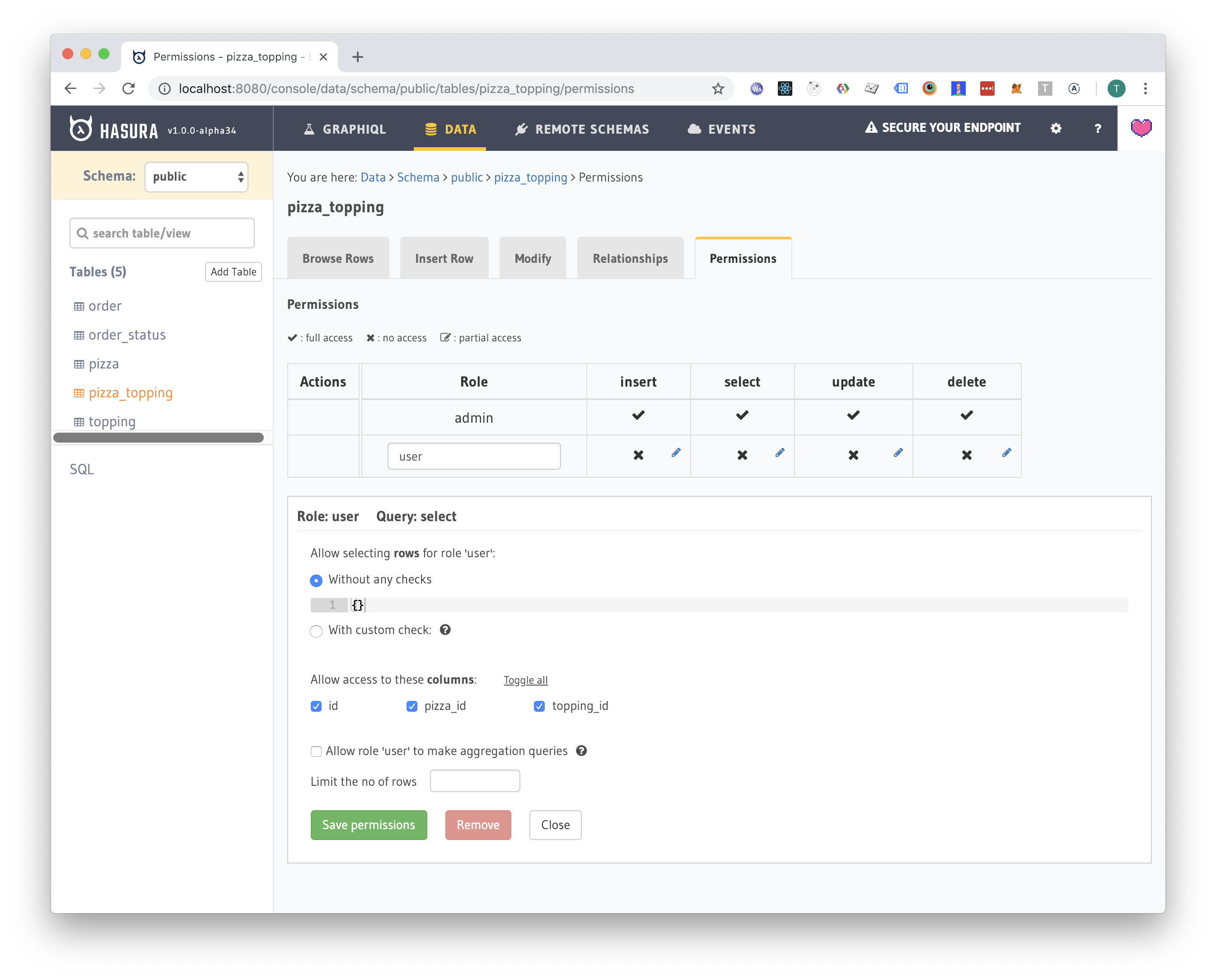
Pizza topping permissions
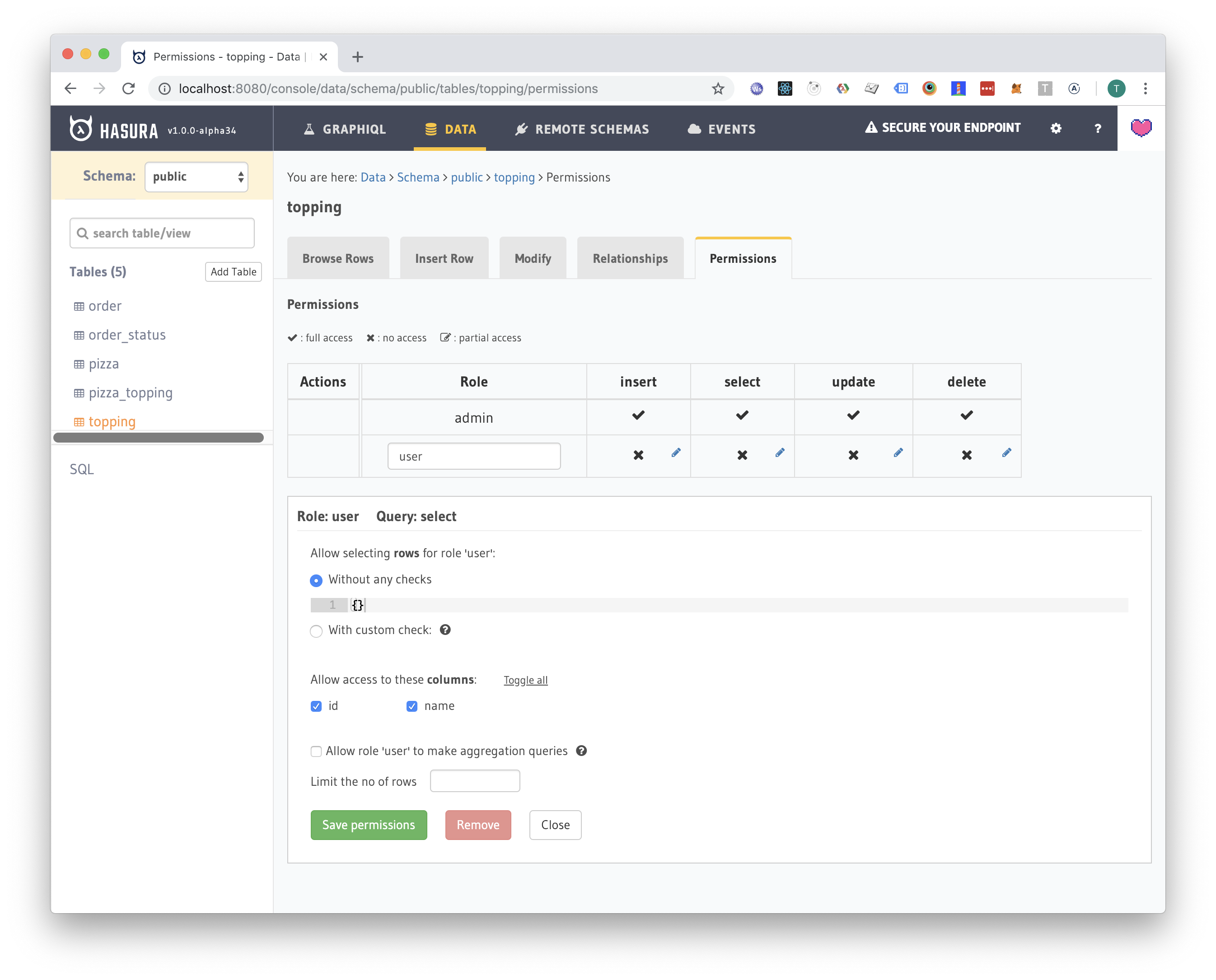
Topping permissions
Remote schema
We could allow the user to insert orders to the database and have Hasura to save the value of x-hasura-user-id header to order's user_id column and that would be it.
But in the real world, we want to execute some business logic when the user places an order. Such business logic can be sending emails, notifications, processing payments and such.
I have implemented a simple NodeJS application which exposes a single GraphQL mutation called createOrder. We can glue the schema to the Hasura schema using Hasura's "Remote Schemas" feature:
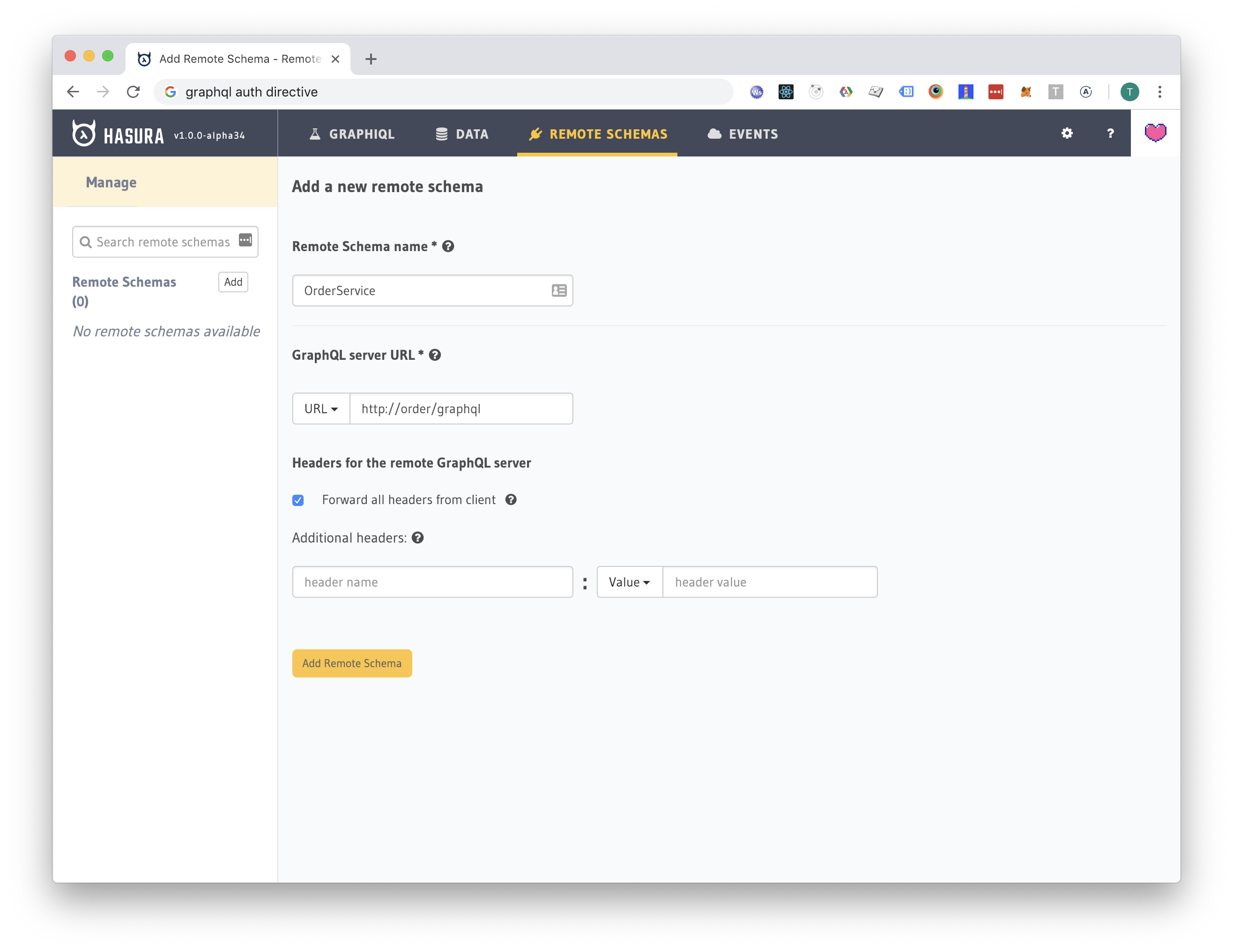
The NodeJS application now handles the createOrder mutation. Also, we have a place where we can implement all the business logic we want.
You can find the source code for the NodeJS application here.
Versioning the metadata
At this point, you might be thinking that we just saved a bunch of data into a database. How are we going to promote these changes from one environment to another?
We can export the Hasura metadata by using the following command:
hasura metadata export
This generates a file that contains all the metadata about the database. We can add this file to our Git repository which means that our metadata is now under version control 🎉.
When we are ready to promote our metadata changes to another environment, we can do this with the following command:
hasura metadata apply
Trying it out
Let's try out our API. First we need to add some data to the database though:
INSERT INTO topping (id, name) VALUES (1, 'Mozzarella cheese');
INSERT INTO topping (id, name) VALUES (2, 'Provolone cheese');
INSERT INTO topping (id, name) VALUES (3, 'Pepperoni');
INSERT INTO topping (id, name) VALUES (4, 'Mushrooms');
INSERT INTO topping (id, name) VALUES (5, 'Marinara sauce');
SELECT setval('topping_id_seq', (SELECT max(id) FROM topping));
INSERT INTO pizza (id, name, price) VALUES (1, 'Pepperoni', 11);
INSERT INTO pizza (id, name, price) VALUES (2, 'Margherita', 9);
SELECT setval('pizza_id_seq', (SELECT max(id) FROM pizza));
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (1, 1);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (1, 2);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (1, 3);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (1, 4);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (1, 5);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (2, 1);
INSERT INTO pizza_topping (pizza_id, topping_id) VALUES (2, 5);
Now we can use a GraphQL client to list the pizzas with the following query (using the user's credentials):
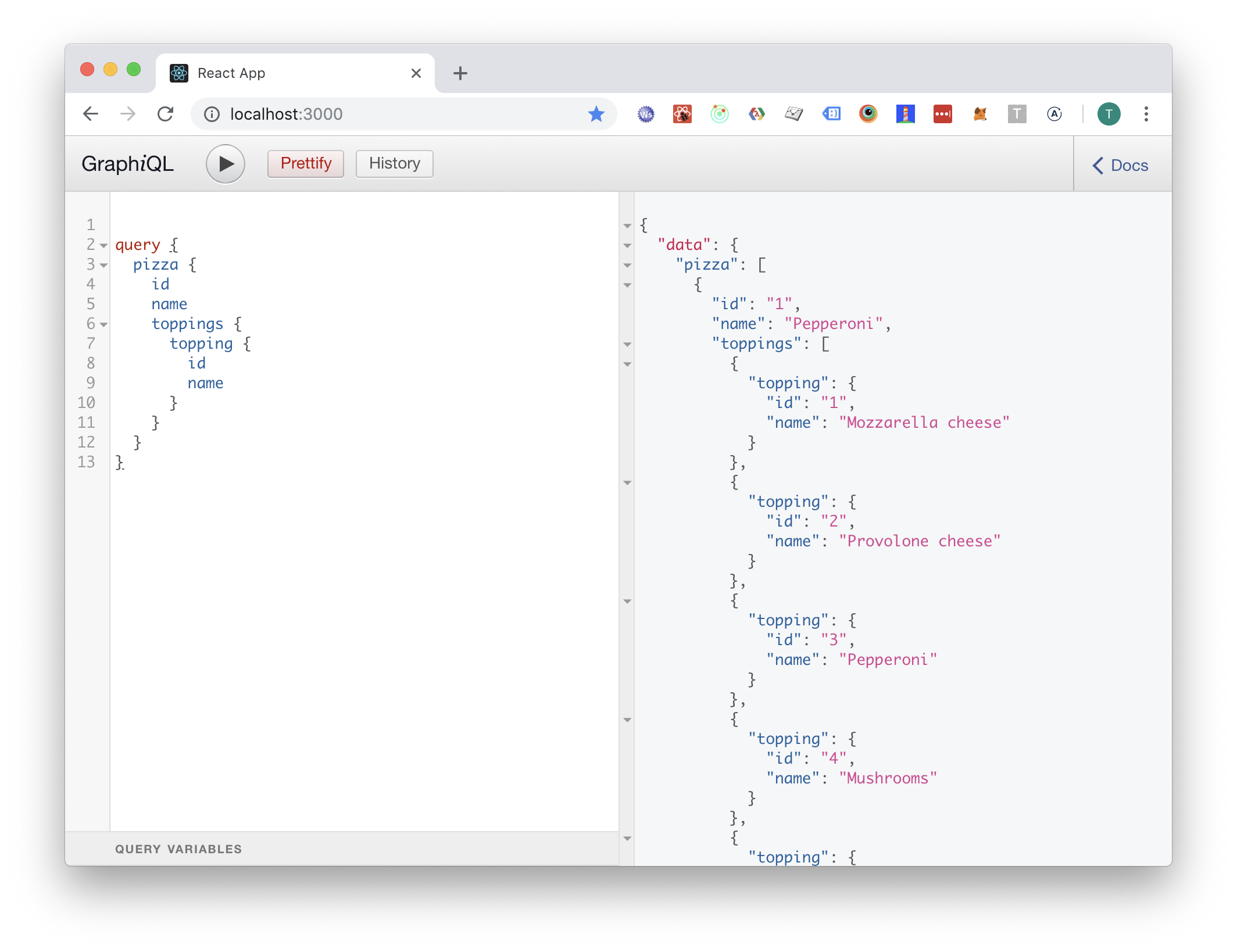
Insert orders and watch changes to them!
Looks like our API is ready for the frontend team 😎.
Discussion
As a backend engineer, you are probably little worried how your system will perform under load. With Hasura you need to take the following into account:
-
Hasura is fast.
-
You can scale Hasura horizontally (subscriptions are implemented by watching database tables directly).
-
The only limitation is the performance of your PostgreSQL instance. Yet, you need to have a lot of concurrent users to saturate a single PostgreSQL instance on modern hardware.
Business logic
You still have to implement some business logic in your backend. With Hasura you have following options:
-
Database triggers and functions. You can implement business logic at some level directly into the database. However, with this option, you are limited to the pretty verbose PL/pgSQL programming language by default.
It seems that there are couple of programming language extension for Postgres: plv8 V8 JavaScript development engine, pgmoon and PL/Java. These solutions will probably have their own limitations.
-
Webhook callbacks. In Hasura, it's possible to add webhooks that react to database events. This allows you to do some async business logic like sending notifications or updating search indices. You can use subscriptions to keep the client up to date.
We could have used this pattern in our pizza-api as well. We could have added a webhook callback to our microservice, which would have updated the database row (ie. payment status). The client would have received the update through a GraphQL subscription.
-
GraphQL Schema Stitching. This is what we used in the example. This approach allows full control of the endpoint implementation. You can, for example, return an error if some side effect fails.
Of course, you don't have to stick with one of these solutions. You can combine them and use the solution that feels the least awkward.
Conclusion
I have thought about using some kind of CRUD generator in my backend stacks for a while. Hasura feels like a solid choice for accelerating your backend development. It has a solid code base written with Haskell (which I'm a fan of). Haskell focuses on correctness and performance, which are assets when implementing something like Hasura.
Hasura definitely has it's uses in my future backend stacks. Nobody enjoys writing simple CRUD endpoints after all. Also, I'm sure that our clients will appreciate not having to pay for work that can be automated.



